
How We Developed the Hilltop Pre-AH Model™
 The Hilltop Institute’s “Predicting Avoidable Hospital Events” model—otherwise known as the Hilltop Pre-AH Model™—originally began with a lunch. In mid-2018, Ian Stockwell, PhD—head of the analytics & research team here at Hilltop—and Howard Haft, MD—executive director of the Maryland Primary Care Program (MDPCP)—met over lunch to discuss the newly established MDPCP. This program is a key element of Maryland’s Total Cost of Care Model and is intended to help primary care providers practice advanced primary care. One of the central ideas of advanced primary care is that primary care providers can (and should) be pro-active, transformational players in a patient’s health care ecosystem, helping patients with disease prevention, chronic disease management, and even the avoidance of unnecessary hospitalizations. Dr. Stockwell, having already developed a predictive model for the Maryland Department of Health on nursing facility admissions, told Dr. Haft that it sounded like a predictive algorithm could be useful in triaging the large patient panels assigned to each primary care practice. Hilltop could develop a model to predict which patients are likely to incur an avoidable hospitalization in the near future, and providers could incorporate these risk predictions into their care processes in order to proactively care for high-risk individuals. Dr. Haft concurred.
The Hilltop Institute’s “Predicting Avoidable Hospital Events” model—otherwise known as the Hilltop Pre-AH Model™—originally began with a lunch. In mid-2018, Ian Stockwell, PhD—head of the analytics & research team here at Hilltop—and Howard Haft, MD—executive director of the Maryland Primary Care Program (MDPCP)—met over lunch to discuss the newly established MDPCP. This program is a key element of Maryland’s Total Cost of Care Model and is intended to help primary care providers practice advanced primary care. One of the central ideas of advanced primary care is that primary care providers can (and should) be pro-active, transformational players in a patient’s health care ecosystem, helping patients with disease prevention, chronic disease management, and even the avoidance of unnecessary hospitalizations. Dr. Stockwell, having already developed a predictive model for the Maryland Department of Health on nursing facility admissions, told Dr. Haft that it sounded like a predictive algorithm could be useful in triaging the large patient panels assigned to each primary care practice. Hilltop could develop a model to predict which patients are likely to incur an avoidable hospitalization in the near future, and providers could incorporate these risk predictions into their care processes in order to proactively care for high-risk individuals. Dr. Haft concurred.
The model-building process took about eight months. The first step, which took about three months, was a comprehensive literature review. We sought to identify, based on previously published research, which risk factors appeared to be predictive of avoidable hospital events. At Hilltop, we view this as a crucial element of predictive model development. Predictive models can, at one extreme, be “black boxes.” It is entirely possible to skip the literature review and feed raw claims into a complex neural network and allow the algorithm to find relationships between (for example) claim-level diagnosis codes and the outcome of choice (in this case, the occurrence of an avoidable hospital event). However, a black-box method of model development makes it difficult to meaningfully determine why certain patients have high (or low) risk scores. We knew that, for this model, we needed maximum transparency. We needed to make a model that identified high-risk patients in a way that allowed care providers to know why a certain patient was high-risk.
The literature review generated a list of about 200 risk factors that have been shown to be predictive of avoidable hospital events. We knew it was important for these risk factors to be operationalizable in administrative claims. The model was set to use Medicare fee-for-service claims, and even though a certain claim (an individual’s current blood glucose level, for example) might be predictive of avoidable hospitalization, this information is not available in administrative claims, so we couldn’t use this risk factor. We also knew that we would also have patient ZIP codes, so we took the time to create a library of about 40 social determinants of health, with the intention of capturing elements of an individual’s environment that may determine their risk of avoidable hospitalizations. We used various publicly available data sources to create these risk factors at the ZIP code level.
The next step was coding. This was the “needle-in-a-haystack” phase of model development. We were swimming in data—tens of millions of claims for hundreds of thousands of patients in practices participating in the MDPCP—but we needed to turn the data into the meaningful risk factors we had identified in the previous step. We used a combination of existing code, further research, and internal Hilltop expertise to turn the risk factors from words on a page to lines of code in a script. We also developed a dual-version coding system (one version in SAS, one version in Stata) to debug and cross-check. This took about three and a half months.
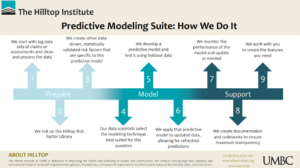 Next, we were ready to develop the model. We had the data and the risk factors and had to decide which model to use to best identify individuals at a high risk of incurring avoidable hospital events. There are many different models that can accomplish this, each with its particular strengths and weaknesses. We knew that we wanted something transparent, stable, and flexible. We were designing a model that could be in production for years, so we wanted to be able to add risk factors. We settled on a discrete time survival model that is operationalized as a person-month multivariable logistic regression. Once we had decided on this modeling strategy, it took a couple of weeks to generate the first internal estimates, and another month to fine-tune the modeling process.
Next, we were ready to develop the model. We had the data and the risk factors and had to decide which model to use to best identify individuals at a high risk of incurring avoidable hospital events. There are many different models that can accomplish this, each with its particular strengths and weaknesses. We knew that we wanted something transparent, stable, and flexible. We were designing a model that could be in production for years, so we wanted to be able to add risk factors. We settled on a discrete time survival model that is operationalized as a person-month multivariable logistic regression. Once we had decided on this modeling strategy, it took a couple of weeks to generate the first internal estimates, and another month to fine-tune the modeling process.
Finally, in September 2019, we moved the model into production. Using three years of data, we trained the model so it would estimate the relationships between our risk factors and the occurrence of future avoidable hospital events. Then, we applied these relationships to the most recent data in order to generate risk scores for each individual in the MDPCP cohort. The first risk scores were released through Maryland’s health information exchange, Chesapeake Regional Information System for our Patients (CRISP), on October 11, 2019. We have been updating, re-training, re-scoring, and releasing new risk scores monthly since then. We monitor model performance each month, and we’re proud to report that the model works well: the top 10% riskiest patients experience about half of all avoidable hospital events in a given month. This means we’re helping primary care providers identify the patients that truly are at risk of future avoidable hospitalizations.
Of course, we didn’t just build the model. We also developed extensive documentation in order to be as transparent as possible with stakeholders and end-users; met many times with our partners at the MDPCP project management office (PMO), CRISP, hMetrix, and other organizations to incorporate their feedback; conducted extensive internal testing in order to make sure that our estimates are as accurate as possible; delivered many trainings and presentations on the model; developed automated processes to conduct data quality checks; and more. Since the model has been in production, we’ve added a feature to let providers know the particular reasons for an individual’s risk, we’ve added risk factors, and we’ve adapted our internal procedures to ensure model quality during the COVID-19 pandemic. Going forward, we plan to use more detailed patient address data in order to better model the social determinants of health. We’re grateful for the support from our partners at the PMO and within Hilltop, and we look forward to helping providers practice precision primary care with this and other models in the coming years.
Morgan Henderson, PhD
Senior Data Scientist
Analytics & Research Team
December 2, 2020